Now we know that the files are stored on the hard drive and the processes can access these files and create new files on the disk. When a process requests for a file the kernel brings the file into the main memory where user process can change, read or access the file. The kernel read the super block to figure out the details about the hard drive and the inode table to find the meta data information of any file. So the kernel reads the inode into the memory whenever any process want to access the data and write it back onto the hard disk when the process is done using the file.
The kernel could read and write the file directly from the hard disk and put it in memory and vice versa but the response time and throughput will be very low in this case because of disks sow data transfer speed.
To minimize the frequency of disk usage/access the kernel keeps a buffer to store the recently accessed files and/or frequently accessed files. This buffer is called the buffer cache.
When the process want to read a file the kernel attempts to read this file in the buffer cache, if the data is found in the buffer cache the data/file is sent to the process. If the file is not found in the buffer cache then the file is read from the disk and then kept in the buffer cache so that it can be made available to the process.
To minimize the disk access frequency the kernel may also implement the pre-caching or write delay functionalities.
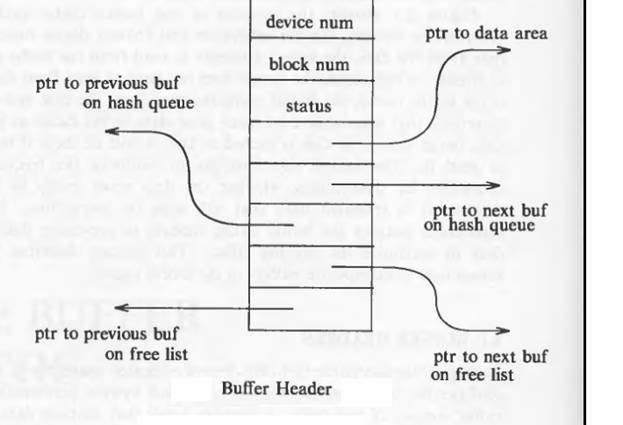
Buffer Headers
When the system initializes the kernel allocates the space for the buffer cache. The buffer cache contains two regions/arts. One for the data/files that will be read from the disk, second the buffer header.The data in the buffer cache corresponds to the logical blocks of the disk block of file system. The buffer cache is “in memory” representation of the disk blocks. This mapping is temporary as the kernel may wish t load some other files’ data into the cache at some later stage.
There will never be a case when the buffer has two entries for the same file on disk as this could lead to inconsistencies. There is only and only one copy of a file in the buffer.
The buffer header contains the metadata information like device number and the block number range for which this buffer holds the data. It stores the logical device number and not the physical device number. The buffer header also contains pointer to a data array for the buffer (i.e. pointer to the data region) .
The buffer header also contains the status of the buffer. The status of the buffer could be
- Locked/unlocked
- Buffer contains a valid data or not.
- Whether the kernel should write the contents to disk immediately or before reassigning the buffer(write delay)
- Kernel is currently reading the data or writing the data.
- Is there any process waiting for the buffer to get free.
Structure of the buffer pool
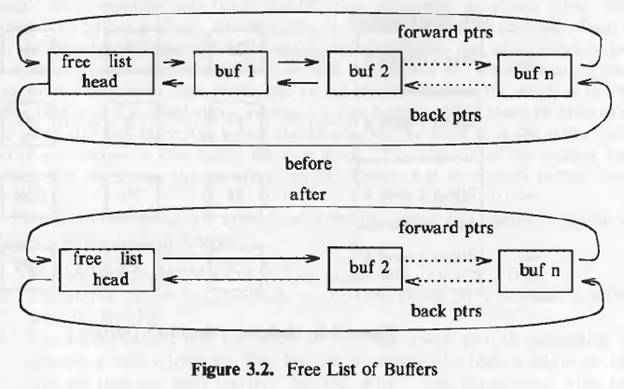
The kernel caches the least recently used data into the buffer pool. Once a balck from buffer pool is allocated for a file of the system this bliock cannot be used for any other file’s data. The kernel also maintains a free list of buffers. The free list is a doubly circular list of buffers.When kernel wants to allocate any buffer it removes a node from the free list, usually from the beginning of list but is could take it from middle of the list too. When kernel frees a node from the buffer list it adds this free node at the end of the free list.
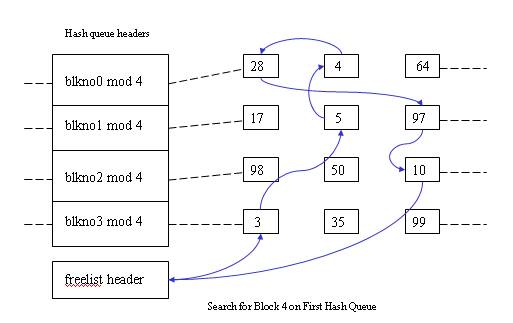
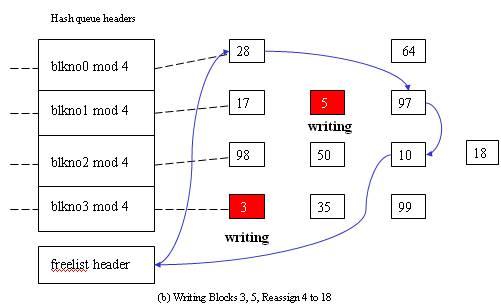
When kernel want to access the disk it searches the buffer pool for a particular device number-block number combination (which is maintained in the buffer header). The entire buffer pool is organized as queues hashed as a function of device number-block number combination. The figure down below shows the buffers on their hash queues.
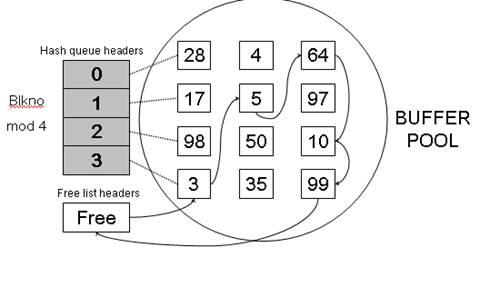
The important thing to note here is that no two nodes in the buffer pool can contain the data of same disk block i.e. same file.
Scenarios of retrieval of buffer
High level kernel algorithms in file subsystem invoke the algorithms of buffer pool to manage the buffer cache. The algorithm for reading and writing disk blocks uses the algorithm getblk to allocate buffer from the pool.
The five typical scenarios that kernel may follow in getblk to allocate a buffer in the disk block are
- Block in the hash queue, and its buffer is free.
- Cannot find block on the hash queue => allocate a buffer from free list.
- Cannot find block on the hash queue => allocate a buffer from free list but buffer on the free list marked “delayed write” => flush “delayed write” buffer and allocate another buffer.
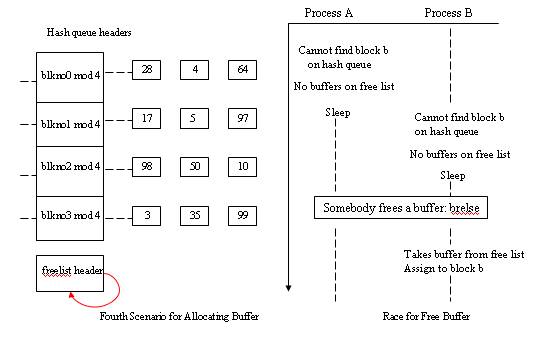
- Cannot find block on the hash queue and free list of buffer also empty.
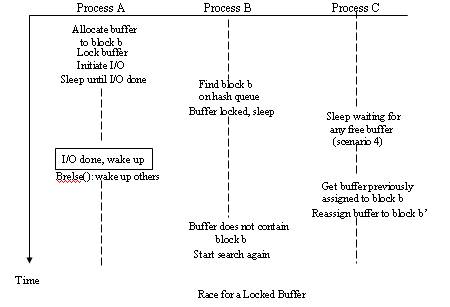
- Block in the hash queue, but buffer is busy.
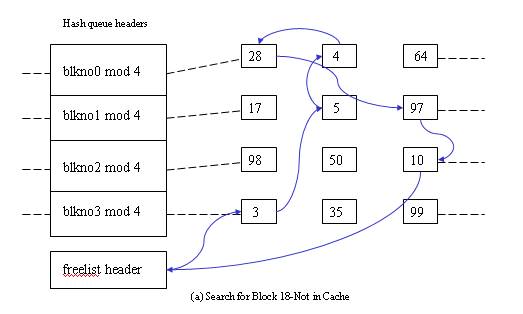
Before continuing to other scenarios lets see what happens after the buffer is allocated. The kernel may read the data, manipulate it and/or change it in the buffer. While doing so the kernel marks the buffer as busy so that no other process can access this block. When the kernel is done using this block it releases the buffer using brelse algorithm.

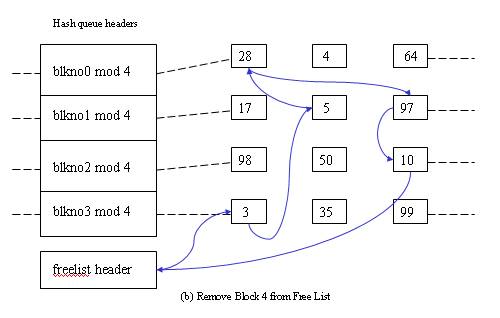
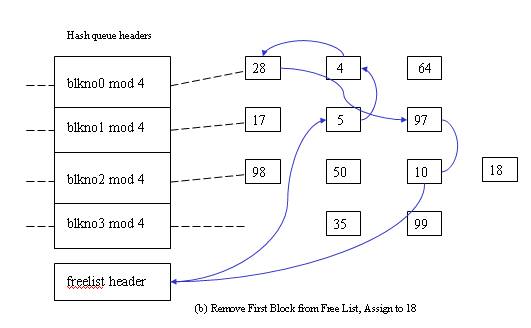
The second scenario - Cannot find block on the hash queue => allocate a buffer from free list.
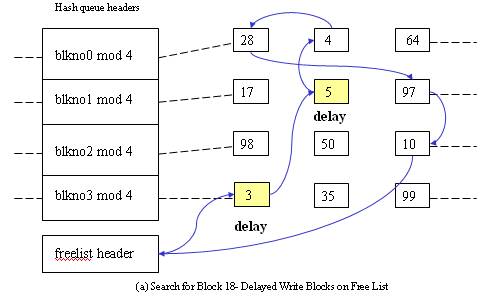
The third scenario - Cannot find block on the hash queue => allocate a buffer from free list but buffer on the free list marked “delayed write” => flush “delayed write” buffer and allocate another buffer.
The fourth scenario - Cannot find block on the hash queue and free list of buffer also empty.
- The fifth scenario - Block in the hash queue, but buffer is busy.
Algorithms for Reading and writing disk blocks



Advantages of the buffer cache
- Uniform disk access => system design simpler
- Copying data from user buffers to system buffers => eliminates the need for special alignment of user buffers.
- Use of the buffer cache can reduce the amount of disk traffic.
- Single image of of disk blocks contained in the cache => helps insure file system integrity
Disadvantages of the buffer cache
- Delayed write => vulnerable to crashes that leave disk data in incorrect state
- An extra data copy when reading and writing to and from user processes => slow down when transmitting large data
No comments:
Post a Comment